
TL;DR
Overview
What?
We estimate the radiance field of large-scale dynamic areas from multiple vehicle captures under varying environmental conditions.
Why?
Previous works in this domain are either restricted to static environments, do not scale to more than a single short video, or struggle to separately represent dynamic object instances.
How?
-
We present a decomposable multi-level neural scene graph representation that scales to dynamic urban environments with thousands of images from dozens of sequences with hundreds of fast-moving objects.
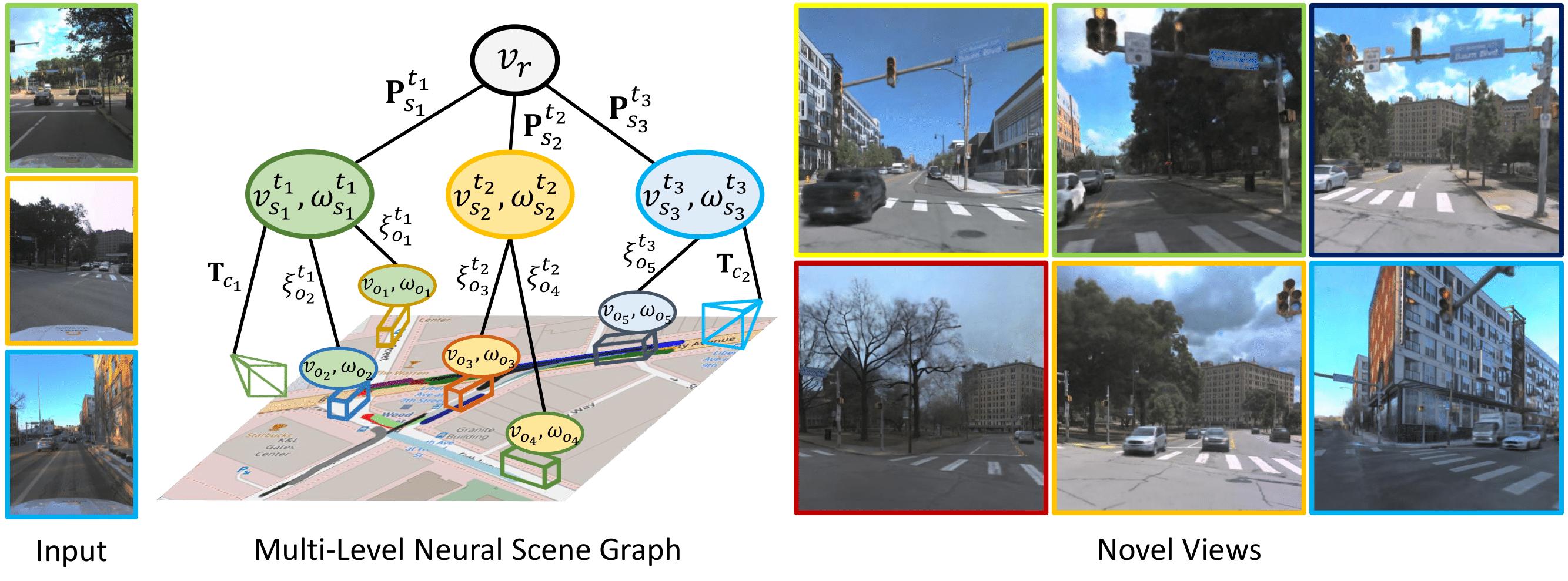 Each dynamic object $v_o$ is associated with a sequence node $v_s^t$ and time $t$. The sequence nodes are registered in a common world frame at the root node $v_r$ through the vehicle poses $\mathbf{P}_s^t$, while the dynamic objects are localized w.r.t. the sequence node with pose $\xi^t$. Each camera $c$ is associated with an ego-vehicle position, \ie node $v_s^t$, through the extrinsic calibration $\mathbf{T}_c$. The sequence and object nodes hold latent codes $\omega$ that condition the radiance field, synthesizing novel views in various conditions with distinct dynamic objects.
Each dynamic object $v_o$ is associated with a sequence node $v_s^t$ and time $t$. The sequence nodes are registered in a common world frame at the root node $v_r$ through the vehicle poses $\mathbf{P}_s^t$, while the dynamic objects are localized w.r.t. the sequence node with pose $\xi^t$. Each camera $c$ is associated with an ego-vehicle position, \ie node $v_s^t$, through the extrinsic calibration $\mathbf{T}_c$. The sequence and object nodes hold latent codes $\omega$ that condition the radiance field, synthesizing novel views in various conditions with distinct dynamic objects. -
To enable efficient training and rendering, we develop a fast composite ray sampling and rendering scheme.
 If a ray intersects with an object $v_o$, we sample from both an efficient proposal network $\sigma_\text{prop}$ and a dynamic radiance field $\psi$. We condition each with the latents $\omega$ of the respective nodes. The PDF along the ray is a mixture of all node densities that intersect with the ray. The transmittance $U$ drops at the first surface intersection (tree) where further samples will concentrate.
If a ray intersects with an object $v_o$, we sample from both an efficient proposal network $\sigma_\text{prop}$ and a dynamic radiance field $\psi$. We condition each with the latents $\omega$ of the respective nodes. The PDF along the ray is a mixture of all node densities that intersect with the ray. The transmittance $U$ drops at the first surface intersection (tree) where further samples will concentrate. -
To test our approach in urban driving scenarios, we introduce a new, novel view synthesis benchmark.
 We choose two urban geographic areas, one residential (left) and one downtown (right). We extract sequences with heterogeneous capturing conditions from these areas using Argoverse 2 as data source. We improve the initial GPS-based alignment with an offline ICP procedure.
We choose two urban geographic areas, one residential (left) and one downtown (right). We extract sequences with heterogeneous capturing conditions from these areas using Argoverse 2 as data source. We improve the initial GPS-based alignment with an offline ICP procedure.
Comparison to state-of-the-art
Our approach outperforms prior art by a significant margin on both established and our proposed benchmark while being faster in training and rendering. We provide qualitative illustrations below. Note that all results are rendered from a single model trained on multiple sequences.


















Poster
BibTeX
@InProceedings{ml-nsg,
author = {Fischer, Tobias and Porzi, Lorenzo, and Rota Bul\`{o}, Samuel and Pollefeys, Marc and Kontschieder, Peter},
title = {Multi-Level Neural Scene Graphs for Dynamic Urban Environments},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
Tobias Fischer
Tobias Fischer is a Ph.D. student at the Computer Vision and Geometry Group of ETH Zürich.